Two thresholds: auto-revert & patrol
There are two things that I want to do with a vandalism prediction model. Auto-revert at an extremely high level of confidence (SMALL% false-positive -- e.g. 1% or 0.1%) and patrol everything that might be vandalism (LARGE% recall -- e.g. 95% or 97.5%). These two modes correspond to auto-revert bots (like ClueBot NG) and recent changes partolling performed by Wikipedia editors. These two thresholds represent basic values to optimize for that represent a real reduction in the amount of time and energy that Wikipedians need to spend patrolling for vandalism.
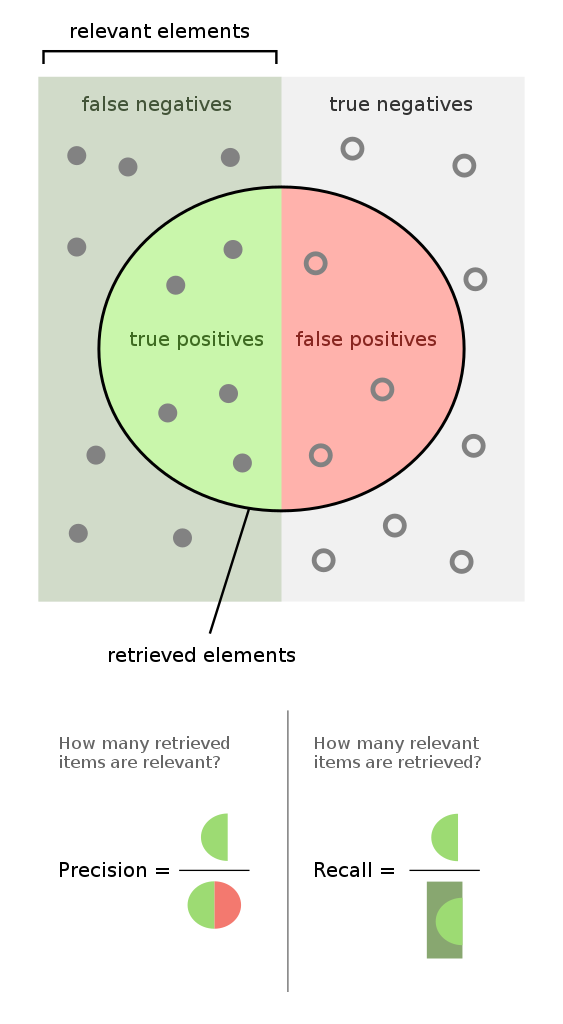 |
| Truth space of a classifier model. [[:commons:File:Precisionrecall.svg]] |
{kind=link}
Optimizing recall for anti-vandal bots
Anti-vandal bots are great in that they operate for free (short of development and maintenance), but they bust behave nicely around humans. A bot that reverts edits is potentially hazardous and so Wikipedians & ClueBot NG maintainers have settled on a 0.1% false-positive rate and claim that they are able to detect 40% of all vandalism. They also claim that, at an older false-positive rate threshold of 1%, the bot was able to catch 55% of all vandalism.
So, vandalism prediction model scholars. Please tell me what recall you get at 1% and 0.1% false-positive rates. As this proportion goes up, humans will need to spend less time and energy reverting vandalism.
Optimizing review-proportion for patrollers
We may never reach the day where anti-vandal bots are able to attain 100% recall. In the meantime, we need to use human judgement to catch everything else. But we can optimize how we make use of this resource (human time and attention) by minimizing how many edits humans will need to review in order to catch some large percentage of the vandalism -- e.g. 95% or 97.5%.
So, vandalism prediction model scholars. Please tell me what proportion of all edits your model must flag as vandalism in order to get 95 and 97.5% recall. As this proportion goes down, humans will need to spend less time and energy reviewing.
Realtime is the killer use-case
This is more of a rant that a request for measurements. A lot of papers explore how much more fitness that they can get using post-hoc measures of activity around an edit. It's no surprise that you can tell whether or not an edit was vandalism easier once you can include "was it reverted?" and "did the reverting editor call it vandalism?" in your model. There's lots of discussion around how these post-hoc models could be used to clean up a print version of Wikipedia, but I'm pretty sure we're never going to do that (at least not really). If we ever did try to reduce views of vandalized articles, we'd probably want do that in realtime. ;)
Whilst the prospect of such a labour-saving device is obviously interesting, should there be some parallel research, possibly qualitative, to respond to the question "What effect would such a system have on new/less committed editors who find that a good-faith change has been bot-magickly reverted?"
ReplyDeleteEven at the 0.1-2.5% levels (which seem amazing BTW), there is obviously the potential to demotivate significant numbers of people. Some sort of adequately responsive review/appeal system, the obvious remedy.
Hey! Thanks for reading. So, it turns out that I came to study this area from more qualitative work around newcomer retention and quality control tools. See my past work: http://www-users.cs.umn.edu/~halfak/publications/The_Rise_and_Decline/halfaker13rise-preprint.pdf and http://www-users.cs.umn.edu/~halfak/publications/Snuggle/halfaker14snuggle-preprint.pdf
ReplyDeleteAs far as I can tell, it's not really the false-positive rates of the algorithm that cause the largest part of the problem, but rather the way that *people* using it behave that has lowered the retention of desirable newcomers. I don't think they are bad people, but they are operating within a process that has not substantially innovated since 2007. I'm building ORES/revscoring while hoping that by making the service open, we can more easily innovate in this space -- and make tools that do *both* quality control *and* newcomer socialization/training in better ways. See my past bloggings re. ORES for more thoughts there. E.g. http://socio-technologist.blogspot.com/2015/12/disparate-impact-of-damage-detection-on.html
Hey! Thanks for your generous response and the links. You're really on it! Halfaker for president!
ReplyDeleteWarm best wishes,
D.