In this post, I want to talk to you about something that I think is really important when communication about what ORES is to a lay audience.
Visualizing ORES
The WMF Comms team is pushing me to make the topic of machine triage much more approachable to a broad audience. So, I have been experimenting with visual metaphors that would make kinds of things that ORES enables easier to understand. I like to make simple diagrams like the one below for the presentations that I give.
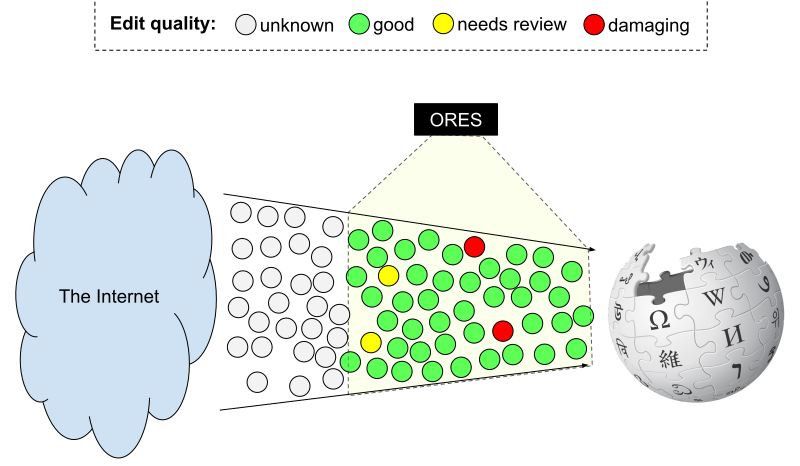 |
The flow of edits from The Internet to Wikipedia are highlighted by ORES
quality prediction models as "good", "needs review" and "damaging".
|
ORES vision
But it occurs to me that a metaphor might be more appropriate. With the right metaphor, I can communicate a lot of important things through implications. With that in mind, I really like using Xray specs as a metaphor for what ORES does. It hits a lot of important points about what using ORES means -- both what makes it powerful and useful and also why we should be cautious when using it.
 |
| A clipping from an old magazine showing fancy sci-fi specs. |
ORES shows you things that you couldn't see easily beforehand. Like a pair of Xray specs, ORES lets you peer into the firehose of edits coming into Wikipedia and see potentially damaging edits stand out in sharp contrast against the background of probably good edits. But just like a pair of sci-fi specs, ORES alters your perception. It implicitly makes subjective statements about what is important (separating the good from the bad) and it might bias you towards looking at the potentially bad with more scrutiny. While this may be the point, it can also be problematic. Profiling an editors work by a small set of statistics is inherently imperfect and the imperfections in the prediction can inevitably lead to biases. So I think it is important to realize that, when using ORES, you're perception is altered in ways that aren't simply more truthful.
So, I hope that the use of this metaphor will help educate ORES users in the level of caution they employ as this socio-technical conversation about how we should use subjective, profiling algorithms as part of the construction of Wikipedia.

