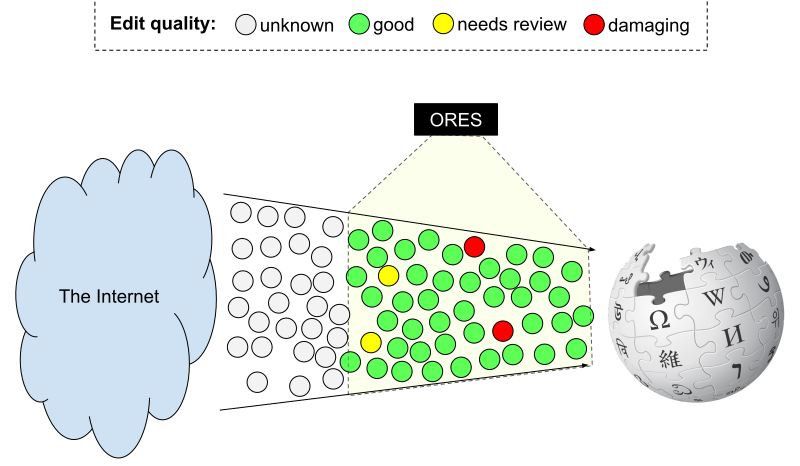
The problem: The damage detection models that ORES supports seems to be overly skeptical of edits by anonymous editors and newcomers.
I've been looking at this problem for a while, but I was recently inspired by by the framing of disparate impact. Thanks to Jacob Thebault-Spieker for suggesting I look at the problem this way.
In United States anti-discrimination law, the theory of disparate impact holds that practices in employment, housing, or other areas may be considered discriminatory and illegal if they have a disproportionate "adverse impact" on persons in a protected class. via Wikipedia's Disparate Impact (CC-BY-SA 4.0)So, let's talk about some terms and how I'd like to apply them to Wikipedia.
Disproportionate adverse impact. The damage detection models that ORES supports are intended to focus attention on potentially damaging edits. Still human judgement is not perfect and there's lot of fun research that suggests that "recommendations" like this can affect people's judgement. So by encouraging Wikipedia's patrollers to look a particular edit, we are likely also making them more likely to find flaws in that edit than if it was not highlighted by ORES. Having an edit rejected can demotivate the editor, but it may be even more concerning that the rejection of content from certain types of editors may lead to coverage biases as the editors most likely to contribute to a particular topic may be discouraged or prevented from editing Wikipedia
Protected class. In US law, it seems that this term is generally reserved for race, gender, and ability. In the case of Wikipedia, we don't know these demographics. They could be involved and I think they likely are, but I think that anonymous editors and newcomers should also be considered a protected class in Wikipedia. Generally, anonymous editors and newcomers are excluded from discussions and therefor subject to the will of experienced editors. I think that this has been having a substantial, negative impact on the quality and coverage of Wikipedia. To state it simply, I think that there are a collection of systemic problems around anonymous editors and newcomers that prevent them from contributing to the dominant store of human knowledge.
So, I think I have a moral obligation to consider the effect that these algorithms have in contributing to these issues and rectifying them. The first and easiest thing I can do is remove the features user.age and user.is_anon from the prediction models. So I did some testing. Here's fitness measures (see AUC) all of the edit quality models with the current and without-user features included.
| wiki | model | current AUC | no-user AUC | diff |
|---|---|---|---|---|
| dewiki | reverted | 0.900 | 0.792 | -0.108 |
| enwiki | reverted | 0.835 | 0.795 | -0.040 |
| enwiki | damaging | 0.901 | 0.818 | -0.083 |
| enwiki | goodfaith | 0.896 | 0.841 | -0.055 |
| eswiki | reverted | 0.880 | 0.849 | -0.031 |
| fawiki | reverted | 0.913 | 0.835 | -0.078 |
| fawiki | damaging | 0.951 | 0.920 | -0.031 |
| fawiki | goodfaith | 0.961 | 0.897 | -0.064 |
| frwiki | reverted | 0.929 | 0.846 | -0.083 |
| hewiki | reverted | 0.874 | 0.800 | -0.074 |
| idwiki | reverted | 0.935 | 0.903 | -0.032 |
| itwiki | reverted | 0.905 | 0.850 | -0.055 |
| nlwiki | reverted | 0.933 | 0.831 | -0.102 |
| ptwiki | reverted | 0.894 | 0.812 | -0.082 |
| ptwiki | damaging | 0.913 | 0.848 | -0.065 |
| ptwiki | goodfaith | 0.923 | 0.863 | -0.060 |
| trwiki | reverted | 0.885 | 0.809 | -0.076 |
| trwiki | damaging | 0.892 | 0.798 | -0.094 |
| trwiki | goodfaith | 0.899 | 0.795 | -0.104 |
| viwiki | reverted | 0.905 | 0.841 | -0.064 |
So to summarize what this table tells us: We'll lose between 0.05 and 0.10 AUC per model which brings us from beating the state of the art to not. That makes the quantitative glands in my brain squirt some anti-dopamine out. It makes me want to run the other way. It's really cool to be able to say "we're beating the state of the art". But on the other hand, it's kind of lame to know "we're doing it at the expense of users who are most sensitive and necessary." So, I've convinced myself. We should deploy these models that look less fit by the numbers, but also reduce the disparate impact on anons and new editors. After all, the actual practical application of the model may very well actually be better despite what the numbers say.
But before I do anything, I need to convince my users. They should have a say in this. At the very least, they should know what is happening. So, next week, I'll start a conversation laying out this argument and advocating for the switch.
One final note. This problem may be a blessing in disguise. By reducing the fitness of our models, we have a new incentive to re-double our efforts toward finding alternative sources of signal to increase the fitness of our models.



.pdf/page136-1024px-Engineering_open_production_efficiency_at_scale_(Invited_talk_%40_Mizzou).pdf.jpg)
.svg/527px-ORES_request_flow_(cache%2Bcelery).svg.png)



