Wednesday, May 24, 2017
Join my reddit AMA about Wikipedia and ethical, transparent AI
Hey folks, I'm doing an experimental Reddit AMA ("ask me anything") in r/IAmA on June 1st at 21:00 UTC. For those who don't know, I create artificial intelligences that support the volunteers who edit Wikipedia. I've been studying the ways that crowds of volunteers build massive, high quality information resources like Wikipedia for over ten years. This AMA will allow me to channel that for new audiences in a different (for us) way. I'll be talking about the work I'm doing with the ethics and transparency of the design of AI, how we think about artificial intelligence on Wikipedia, and ways we’re working to counteract vandalism. I'd love to have your feedback, comments, and questions—preferably when the AMA begins, but also through the ORES talkpage on MediaWiki.
If you'd like to know more about what I do, see my WMF staff user page, this Wired piece about my work or my paper, "The Rise and Decline of an Open Collaboration System: How Wikipedia’s reaction to popularity is causing its decline".
Thursday, October 20, 2016
Best practices for AI in the social spaces: Integrated refutations
So, I was listening to an NPR show titled "Digging into Facebook's File on You". At some point, there was some casual discussion of laws that some countries in the European Union have re. users' ability to review and correct mistakes in data that is stored about them. This made me realize that ORES needs a good mechanism for you to review how the system classifies you and your stuff.
As soon as I realized this, I wrote up a ticket describing my rough thoughts on what a "refutation" system would look like. From https://phabricator.wikimedia.org/T148700:
Build a user-friendly UI for reviewing how ORES has classified you or any query-able slice of activity.On one hand, I'm excited by this idea because I think it will be a very interesting exploration into what kinds of feedback people want to give to ORES' classifications. I think it will provide a good means for humans to disagree with the machine in ways that are effective. It's important that we don't hide false-positive/negative reports somewhere that no one will ever see. It would be better if such reports were available as part of a query result -- so that ORES decision can be flagged and directly challenged by a human.
Include UI & API to refute classifications endpoints (via OAuth).
Include UI to curate "refutations" (suppress & meta-review).
Notes:
- Refutations need freeform text. Freeform text *must* have a suppression system.
- We should include refutations in ORES query results.
- We can borrow from MediaWiki's global user rights (ORES is global) for curation privs.
On the other hand, I'm a little bit embarrassed that this wasn't part of the plan all along. I guess in a way, I expected the wiki to fill this infrastructure -- of critiquing ORES. But critiques on the wiki are hidden from the API that tools use to consume score and relegating them to a less effectual class of data. I feel a little bit stupid that it never occurred to me that humans should be able to affect ORES' output.
Now to find the resources to construct this Meta-ORES system...
Wednesday, June 29, 2016
The end of "lowering barriers" as a metaphor for transition difficulty
I remember sitting on the carpet at CSCW 2014 talking to Gabriel Mugar about boundaries and how people becoming aware of them. I've been working on some thoughts re. "barriers" being the wrong word because one imagines a passive wall of some height/permeability that can be removed or opened -- hence "lowered".
In the case of active socialization as some newcomer is welcomed to some established community, the "wall" is more than "lowered"; an active aid of conveyance across some threshold is provided. Here, Latour's door opener doesn't just make it easy to enter a building but also communicates that you are welcome. If we were to apply the barrier metaphor of a "wall" that might be lowered, we might imagine a simple hole in the wall being the lowest barrier. But when thinking about active socialization, a hole in the wall with a "welcomer" is more open. Does the "welcomer" lower the "wall" further? No. Suddenly the idea of "lowering as barrier" gets in the way of thinking clearly about the difficulty people experience when transitioning from "outside" to "inside" of a community.
In the case of active socialization as some newcomer is welcomed to some established community, the "wall" is more than "lowered"; an active aid of conveyance across some threshold is provided. Here, Latour's door opener doesn't just make it easy to enter a building but also communicates that you are welcome. If we were to apply the barrier metaphor of a "wall" that might be lowered, we might imagine a simple hole in the wall being the lowest barrier. But when thinking about active socialization, a hole in the wall with a "welcomer" is more open. Does the "welcomer" lower the "wall" further? No. Suddenly the idea of "lowering as barrier" gets in the way of thinking clearly about the difficulty people experience when transitioning from "outside" to "inside" of a community.
Sunday, March 13, 2016
Brief discussion: The Effects and Antecedents of Conflict in FLOSS dev.
Hey folks. For this weeks blogging, I'll be reading and thinking about:
A Filippova, H Cho, The Effects and Antecedents of Conflict in Free and Open Source Software Development. CSCW, 2016This isn't a review or really a summary -- just some thoughts I had that I want to share.
Transformational leadership
See https://en.wikipedia.org/wiki/Transformational_leadership
Filippova et al. highlight a "transactional leadership" style as one of the factors mitigating the negative effects of high-conflict FOSS teams.
I don't really like the word "transformational" since, to me, it seems to fail to highlight the key meaning of the term -- collaboration. A transactional leader doesn't own the process of change, but rather works with others to put together a vision and enact a change with other committed individuals. It involves convincing other of a directional change or new effort rather than enforcing it through force or punishment/reward. I think the key insight that transactional leaders have is that they do not own the process of change. At most they can be a key contributor to it. There will need to be a conversation and some sort of consensus before real change can happen. In my practice as a leader of a small group of volunteers developing a FOSS project, I can't imagine operating any other way. I must lead by example -- by making a convincing case for what we should do and allowing myself to be convinced by other. The direction we set will be owned by all. I need my team to feel this ownership and shared identity. This is a trick when there are deadlines and a disagreement threatens delaying substantial work, but in my experience, deadlines aren't that dead and delays can be real opportunities to step back and ask why the disagreement exists in the first place.
In the end, if I can't convince you (gentle reader, my assumed collaborator) that my idea is good and worth pursuing then maybe it's not actually good or worth pursuing. In a way, I see transactional leadership style a lot like code review. If I want to reprogram our team structure/plans, then I should be able to get the changes reviewed and supported by others. In the process of review, we can increase our shared notion of norms/goals and make sure that the implemented changes are actually good!
Different types of conflict
So, I've been studying conflict patterns in Wikipedia for a while, but I've never really dug into the literature about different types of conflict. Of course, it's obvious that there *are* different types. I've written about this in the past around reverts in Wikipedia, but it's much more useful to apply past through on the subject than to inject my own naive point of view. Luckily, Filippova et al. provide a nice summary of Task conflict, Affective conflict, Process conflict, and Normative conflict.
- Task conflict: Conflict about what needs to be done. E.g. do we engineer ORES to use celery workers or do we just plan to have a large pool of independent uwsgi threads? While this can be good in that it brings a diverse perspective of possible implementations, it also might turn into a religious battle over the Right Way To Do Things(TM).
- Affective conflict: AKA drama. Conflict due to bad blood -- relationships between people might cause conflict regardless of any task disagreement. E.g. do we attribute the failure of a team member to complete a task to the complexity of the task or to their general incompetence?
- Process conflict: Disagreements over how to do tasks. E.g. do we require code-review and non-self-merges for *everything* or are there some reasonable exceptions. On the Revision Scoring project, I generally make process declarations that go unchallenged and then we iterate whenever the process seems to be not working. So far, I wouldn't really say that this has escalated to "conflict" yet, but I could see how it might.
- Normative conflict: Disagreements about "group function". E.g. do we generally pursue a caution-first strategy or an open-first strategy (everything is open until a problem arises vs. everything is closed until we know we can safely open it)? This is a discussion that I'd like to come back to in a future blog post as I'm very opinionated about how the norms of Wikipedia (bold inclusionism & openness) should be extended to the software development community around MediaWiki.
Sunday, March 6, 2016
Revscoring 1.0 and some demos
| The "Revision Scoring" logo |
I've mostly been traveling recently, but I have got some hacking in. There are a few things I want to share.
- I just released the revscoring 1.0 -- revscoring is the library that powers ORES. I developed it to make building and deploying machine learning models as services easier.
- I wrote up an ipython notebook that demonstrates how to build a machine learning classifier to detect vandalism in Wikipedia.
- I just finished writing up an ipython notebook that digs into how the feature extraction system in revscoring works.
Next week, I hope to be showing you some more about the disparate impact of damage detectors on anons. Stay tuned.
Sunday, January 24, 2016
Notes on writing a Wikipedia Vandalism detection paper
Hey folks. I've been reviewing Wikipedia vandalism detection papers -- which have been an active genre since ~2008. I'll be writing a more substantial summary of the field at some point, but for now, I just want to share some notes on what I (a Wikipedia vandalism detection practitioner) want to see in future work in this area.
Two thresholds: auto-revert & patrol
There are two things that I want to do with a vandalism prediction model. Auto-revert at an extremely high level of confidence (SMALL% false-positive -- e.g. 1% or 0.1%) and patrol everything that might be vandalism (LARGE% recall -- e.g. 95% or 97.5%). These two modes correspond to auto-revert bots (like ClueBot NG) and recent changes partolling performed by Wikipedia editors. These two thresholds represent basic values to optimize for that represent a real reduction in the amount of time and energy that Wikipedians need to spend patrolling for vandalism.
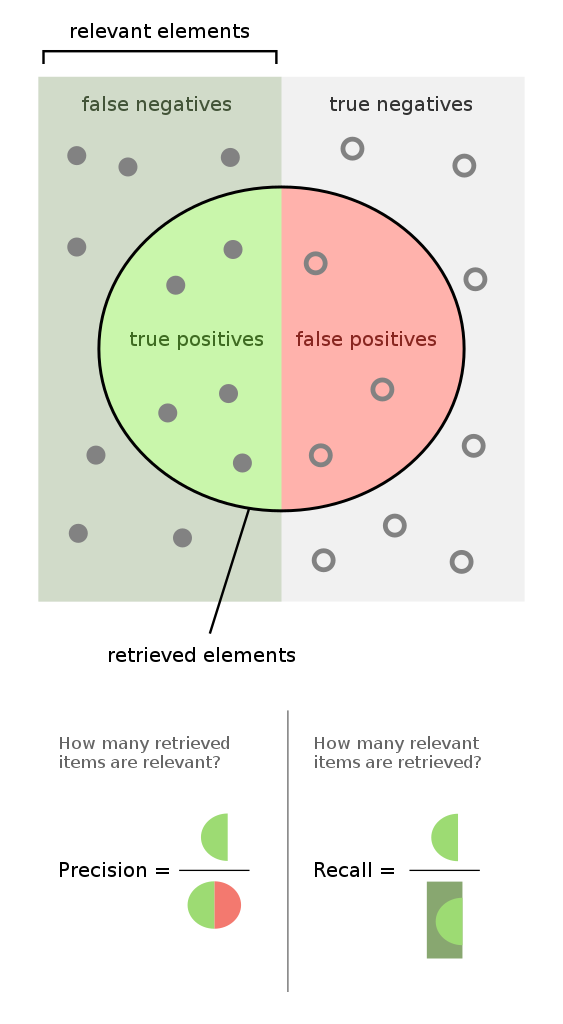 |
| Truth space of a classifier model. [[:commons:File:Precisionrecall.svg]] |
{kind=link}
Optimizing recall for anti-vandal bots
Anti-vandal bots are great in that they operate for free (short of development and maintenance), but they bust behave nicely around humans. A bot that reverts edits is potentially hazardous and so Wikipedians & ClueBot NG maintainers have settled on a 0.1% false-positive rate and claim that they are able to detect 40% of all vandalism. They also claim that, at an older false-positive rate threshold of 1%, the bot was able to catch 55% of all vandalism.
So, vandalism prediction model scholars. Please tell me what recall you get at 1% and 0.1% false-positive rates. As this proportion goes up, humans will need to spend less time and energy reverting vandalism.
Optimizing review-proportion for patrollers
We may never reach the day where anti-vandal bots are able to attain 100% recall. In the meantime, we need to use human judgement to catch everything else. But we can optimize how we make use of this resource (human time and attention) by minimizing how many edits humans will need to review in order to catch some large percentage of the vandalism -- e.g. 95% or 97.5%.
So, vandalism prediction model scholars. Please tell me what proportion of all edits your model must flag as vandalism in order to get 95 and 97.5% recall. As this proportion goes down, humans will need to spend less time and energy reviewing.
Realtime is the killer use-case
This is more of a rant that a request for measurements. A lot of papers explore how much more fitness that they can get using post-hoc measures of activity around an edit. It's no surprise that you can tell whether or not an edit was vandalism easier once you can include "was it reverted?" and "did the reverting editor call it vandalism?" in your model. There's lots of discussion around how these post-hoc models could be used to clean up a print version of Wikipedia, but I'm pretty sure we're never going to do that (at least not really). If we ever did try to reduce views of vandalized articles, we'd probably want do that in realtime. ;)
Sunday, December 6, 2015
Disparate impact of damage-detection on anonymous Wikipedia editors
Today, I'm writing briefly about a problem that I expect to be studying and trying to fix over the course of the next few weeks.
The problem: The damage detection models that ORES supports seems to be overly skeptical of edits by anonymous editors and newcomers.
I've been looking at this problem for a while, but I was recently inspired by by the framing of disparate impact. Thanks to Jacob Thebault-Spieker for suggesting I look at the problem this way.
Disproportionate adverse impact. The damage detection models that ORES supports are intended to focus attention on potentially damaging edits. Still human judgement is not perfect and there's lot of fun research that suggests that "recommendations" like this can affect people's judgement. So by encouraging Wikipedia's patrollers to look a particular edit, we are likely also making them more likely to find flaws in that edit than if it was not highlighted by ORES. Having an edit rejected can demotivate the editor, but it may be even more concerning that the rejection of content from certain types of editors may lead to coverage biases as the editors most likely to contribute to a particular topic may be discouraged or prevented from editing Wikipedia
Protected class. In US law, it seems that this term is generally reserved for race, gender, and ability. In the case of Wikipedia, we don't know these demographics. They could be involved and I think they likely are, but I think that anonymous editors and newcomers should also be considered a protected class in Wikipedia. Generally, anonymous editors and newcomers are excluded from discussions and therefor subject to the will of experienced editors. I think that this has been having a substantial, negative impact on the quality and coverage of Wikipedia. To state it simply, I think that there are a collection of systemic problems around anonymous editors and newcomers that prevent them from contributing to the dominant store of human knowledge.
So, I think I have a moral obligation to consider the effect that these algorithms have in contributing to these issues and rectifying them. The first and easiest thing I can do is remove the features user.age and user.is_anon from the prediction models. So I did some testing. Here's fitness measures (see AUC) all of the edit quality models with the current and without-user features included.
The problem: The damage detection models that ORES supports seems to be overly skeptical of edits by anonymous editors and newcomers.
I've been looking at this problem for a while, but I was recently inspired by by the framing of disparate impact. Thanks to Jacob Thebault-Spieker for suggesting I look at the problem this way.
In United States anti-discrimination law, the theory of disparate impact holds that practices in employment, housing, or other areas may be considered discriminatory and illegal if they have a disproportionate "adverse impact" on persons in a protected class. via Wikipedia's Disparate Impact (CC-BY-SA 4.0)So, let's talk about some terms and how I'd like to apply them to Wikipedia.
Disproportionate adverse impact. The damage detection models that ORES supports are intended to focus attention on potentially damaging edits. Still human judgement is not perfect and there's lot of fun research that suggests that "recommendations" like this can affect people's judgement. So by encouraging Wikipedia's patrollers to look a particular edit, we are likely also making them more likely to find flaws in that edit than if it was not highlighted by ORES. Having an edit rejected can demotivate the editor, but it may be even more concerning that the rejection of content from certain types of editors may lead to coverage biases as the editors most likely to contribute to a particular topic may be discouraged or prevented from editing Wikipedia
Protected class. In US law, it seems that this term is generally reserved for race, gender, and ability. In the case of Wikipedia, we don't know these demographics. They could be involved and I think they likely are, but I think that anonymous editors and newcomers should also be considered a protected class in Wikipedia. Generally, anonymous editors and newcomers are excluded from discussions and therefor subject to the will of experienced editors. I think that this has been having a substantial, negative impact on the quality and coverage of Wikipedia. To state it simply, I think that there are a collection of systemic problems around anonymous editors and newcomers that prevent them from contributing to the dominant store of human knowledge.
So, I think I have a moral obligation to consider the effect that these algorithms have in contributing to these issues and rectifying them. The first and easiest thing I can do is remove the features user.age and user.is_anon from the prediction models. So I did some testing. Here's fitness measures (see AUC) all of the edit quality models with the current and without-user features included.
| wiki | model | current AUC | no-user AUC | diff |
|---|---|---|---|---|
| dewiki | reverted | 0.900 | 0.792 | -0.108 |
| enwiki | reverted | 0.835 | 0.795 | -0.040 |
| enwiki | damaging | 0.901 | 0.818 | -0.083 |
| enwiki | goodfaith | 0.896 | 0.841 | -0.055 |
| eswiki | reverted | 0.880 | 0.849 | -0.031 |
| fawiki | reverted | 0.913 | 0.835 | -0.078 |
| fawiki | damaging | 0.951 | 0.920 | -0.031 |
| fawiki | goodfaith | 0.961 | 0.897 | -0.064 |
| frwiki | reverted | 0.929 | 0.846 | -0.083 |
| hewiki | reverted | 0.874 | 0.800 | -0.074 |
| idwiki | reverted | 0.935 | 0.903 | -0.032 |
| itwiki | reverted | 0.905 | 0.850 | -0.055 |
| nlwiki | reverted | 0.933 | 0.831 | -0.102 |
| ptwiki | reverted | 0.894 | 0.812 | -0.082 |
| ptwiki | damaging | 0.913 | 0.848 | -0.065 |
| ptwiki | goodfaith | 0.923 | 0.863 | -0.060 |
| trwiki | reverted | 0.885 | 0.809 | -0.076 |
| trwiki | damaging | 0.892 | 0.798 | -0.094 |
| trwiki | goodfaith | 0.899 | 0.795 | -0.104 |
| viwiki | reverted | 0.905 | 0.841 | -0.064 |
So to summarize what this table tells us: We'll lose between 0.05 and 0.10 AUC per model which brings us from beating the state of the art to not. That makes the quantitative glands in my brain squirt some anti-dopamine out. It makes me want to run the other way. It's really cool to be able to say "we're beating the state of the art". But on the other hand, it's kind of lame to know "we're doing it at the expense of users who are most sensitive and necessary." So, I've convinced myself. We should deploy these models that look less fit by the numbers, but also reduce the disparate impact on anons and new editors. After all, the actual practical application of the model may very well actually be better despite what the numbers say.
But before I do anything, I need to convince my users. They should have a say in this. At the very least, they should know what is happening. So, next week, I'll start a conversation laying out this argument and advocating for the switch.
One final note. This problem may be a blessing in disguise. By reducing the fitness of our models, we have a new incentive to re-double our efforts toward finding alternative sources of signal to increase the fitness of our models.
Subscribe to:
Posts (Atom)